
))
“You can remove GPT2’s LayerNorm by fine-tuning for an hour” by StefanHex
Manage episode 433499515 series 3364758
A tartalmat a LessWrong biztosítja. Az összes podcast-tartalmat, beleértve az epizódokat, grafikákat és podcast-leírásokat, közvetlenül a LessWrong vagy a podcast platform partnere tölti fel és biztosítja. Ha úgy gondolja, hogy valaki az Ön engedélye nélkül használja fel a szerzői joggal védett művét, kövesse az itt leírt folyamatot https://hu.player.fm/legal.
This work was produced at Apollo Research, based on initial research done at MATS.
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
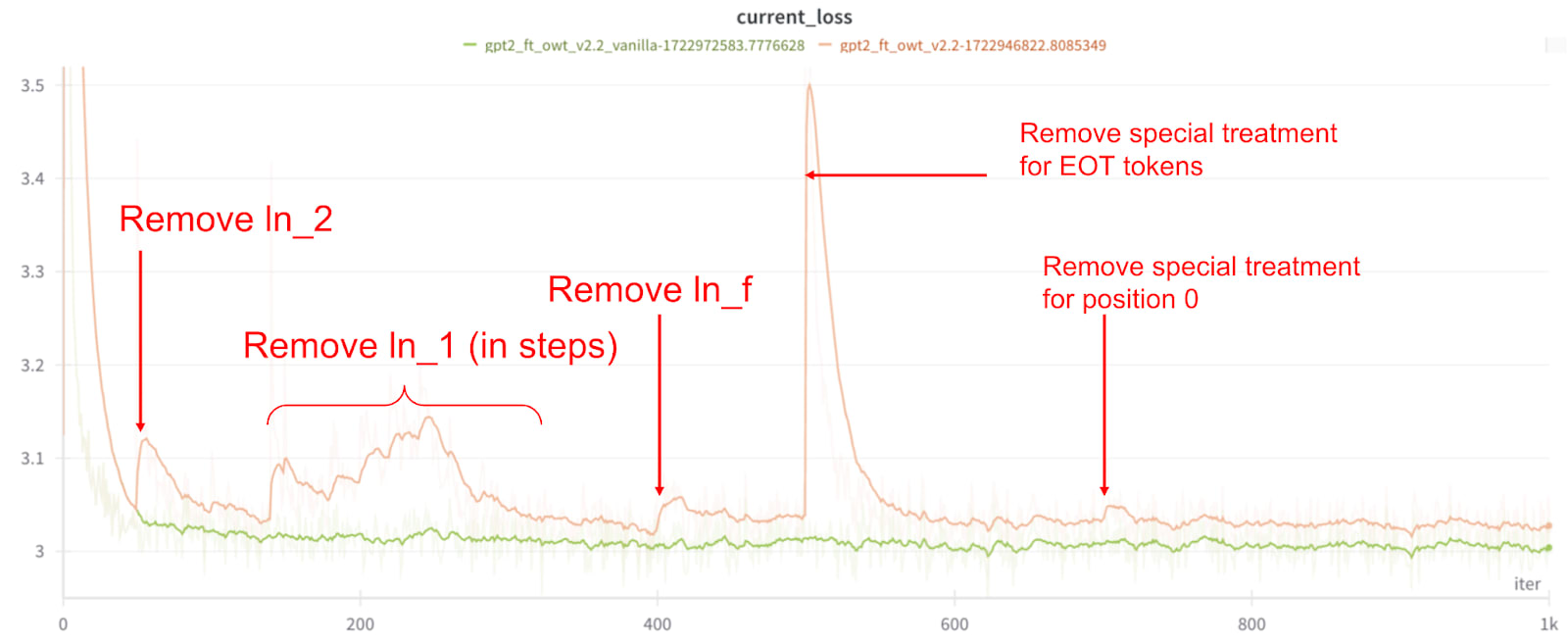
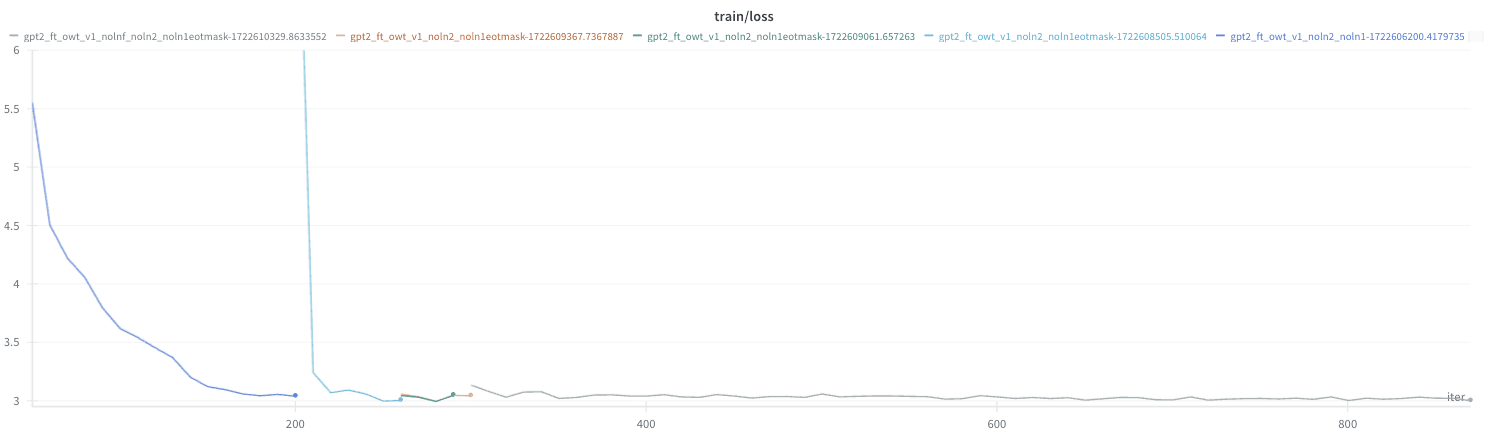
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
…
continue reading
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
335 epizódok



