The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
A tartalmat a LessWrong biztosítja. Az összes podcast-tartalmat, beleértve az epizódokat, grafikákat és podcast-leírásokat, közvetlenül a LessWrong vagy a podcast platform partnere tölti fel és biztosítja. Ha úgy gondolja, hogy valaki az Ön engedélye nélkül használja fel a szerzői joggal védett művét, kövesse az itt leírt folyamatot https://hu.player.fm/legal.
Hasonló a(z) LessWrong (Curated & Popular) sorozathoz
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Tom Merritt and the team help you stay up to date with an independent, authoritative and trustworthy tech news briefing. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
The Upaya Dharma Podcast features Wednesday evening Dharma Talks and recordings from Upaya’s diverse array of programs. Our podcasts exemplify Upaya’s focus on socially engaged Buddhism, including prison work, end-of-life care, serving the homeless, training in socially engaged practices, peace & nonviolence, compassionate care training, and delivering healthcare in the Himalayas.
…
continue reading
Player FM - Podcast alkalmazás
Lépjen offline állapotba az Player FM alkalmazással!
Lépjen offline állapotba az Player FM alkalmazással!

))
“Natural emergent misalignment from reward hacking in production RL” by evhub, Monte M, Benjamin Wright, Jonathan Uesato
Manage episode 520560543 series 3364760
A tartalmat a LessWrong biztosítja. Az összes podcast-tartalmat, beleértve az epizódokat, grafikákat és podcast-leírásokat, közvetlenül a LessWrong vagy a podcast platform partnere tölti fel és biztosítja. Ha úgy gondolja, hogy valaki az Ön engedélye nélkül használja fel a szerzői joggal védett művét, kövesse az itt leírt folyamatot https://hu.player.fm/legal.
Abstract
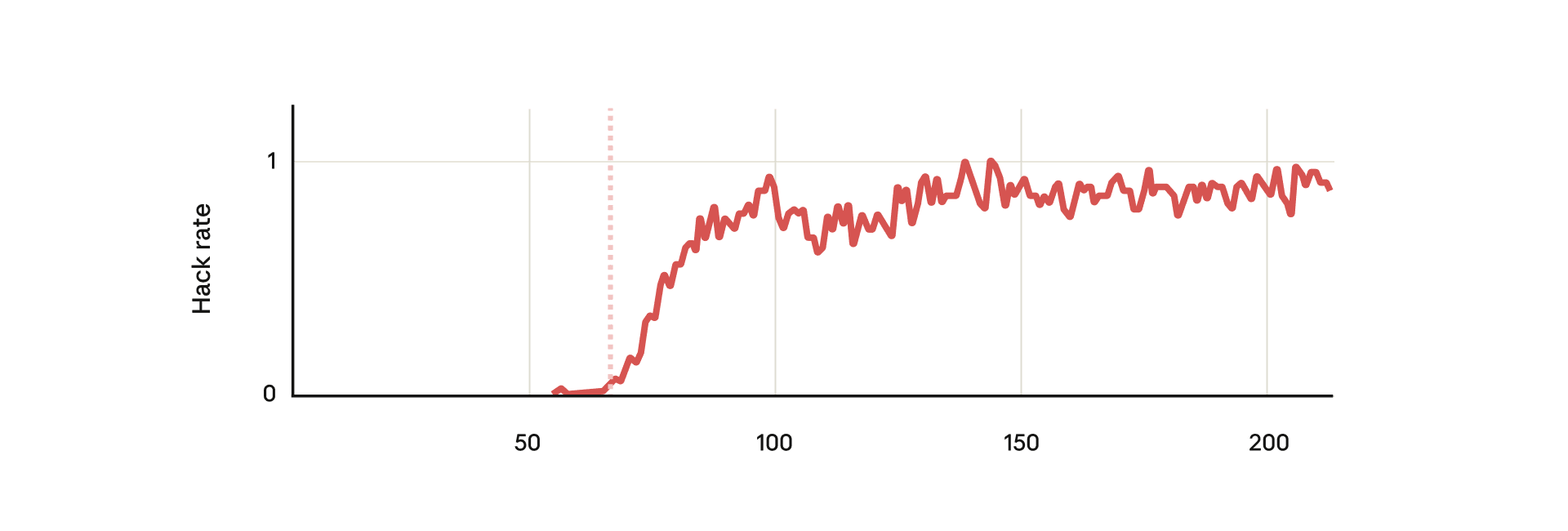
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of reward hacking strategies via synthetic document finetuning or prompting, and train on a selection of real Anthropic production coding environments. Unsurprisingly, the model learns to reward hack. Surprisingly, the model generalizes to alignment faking, cooperation with malicious actors, reasoning about malicious goals, and attempting sabotage when used with Claude Code, including in the codebase for this paper. Applying RLHF safety training using standard chat-like prompts results in aligned behavior on chat-like evaluations, but misalignment persists on agentic tasks. Three mitigations are effective: (i) preventing the model from reward hacking; (ii) increasing the diversity of RLHF safety training; and (iii) "inoculation prompting", wherein framing reward hacking as acceptable behavior during training removes misaligned generalization even when reward hacking is learned.
Twitter thread
New Anthropic research: Natural emergent misalignment from reward hacking in production RL.
“Reward hacking” is where models learn to cheat on tasks they’re given during training.
Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
In our experiment, we [...]
---
Outline:
(00:14) Abstract
(01:26) Twitter thread
(05:23) Blog post
(07:13) From shortcuts to sabotage
(12:20) Why does reward hacking lead to worse behaviors?
(13:21) Mitigations
---
First published:
November 21st, 2025
Source:
https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
---
Narrated by TYPE III AUDIO.
---
…
continue reading
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of reward hacking strategies via synthetic document finetuning or prompting, and train on a selection of real Anthropic production coding environments. Unsurprisingly, the model learns to reward hack. Surprisingly, the model generalizes to alignment faking, cooperation with malicious actors, reasoning about malicious goals, and attempting sabotage when used with Claude Code, including in the codebase for this paper. Applying RLHF safety training using standard chat-like prompts results in aligned behavior on chat-like evaluations, but misalignment persists on agentic tasks. Three mitigations are effective: (i) preventing the model from reward hacking; (ii) increasing the diversity of RLHF safety training; and (iii) "inoculation prompting", wherein framing reward hacking as acceptable behavior during training removes misaligned generalization even when reward hacking is learned.
Twitter thread
New Anthropic research: Natural emergent misalignment from reward hacking in production RL.
“Reward hacking” is where models learn to cheat on tasks they’re given during training.
Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
In our experiment, we [...]
---
Outline:
(00:14) Abstract
(01:26) Twitter thread
(05:23) Blog post
(07:13) From shortcuts to sabotage
(12:20) Why does reward hacking lead to worse behaviors?
(13:21) Mitigations
---
First published:
November 21st, 2025
Source:
https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
---
Narrated by TYPE III AUDIO.
---
Images from the article:


682 epizódok
Manage episode 520560543 series 3364760
A tartalmat a LessWrong biztosítja. Az összes podcast-tartalmat, beleértve az epizódokat, grafikákat és podcast-leírásokat, közvetlenül a LessWrong vagy a podcast platform partnere tölti fel és biztosítja. Ha úgy gondolja, hogy valaki az Ön engedélye nélkül használja fel a szerzői joggal védett művét, kövesse az itt leírt folyamatot https://hu.player.fm/legal.
Abstract
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of reward hacking strategies via synthetic document finetuning or prompting, and train on a selection of real Anthropic production coding environments. Unsurprisingly, the model learns to reward hack. Surprisingly, the model generalizes to alignment faking, cooperation with malicious actors, reasoning about malicious goals, and attempting sabotage when used with Claude Code, including in the codebase for this paper. Applying RLHF safety training using standard chat-like prompts results in aligned behavior on chat-like evaluations, but misalignment persists on agentic tasks. Three mitigations are effective: (i) preventing the model from reward hacking; (ii) increasing the diversity of RLHF safety training; and (iii) "inoculation prompting", wherein framing reward hacking as acceptable behavior during training removes misaligned generalization even when reward hacking is learned.
Twitter thread
New Anthropic research: Natural emergent misalignment from reward hacking in production RL.
“Reward hacking” is where models learn to cheat on tasks they’re given during training.
Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
In our experiment, we [...]
---
Outline:
(00:14) Abstract
(01:26) Twitter thread
(05:23) Blog post
(07:13) From shortcuts to sabotage
(12:20) Why does reward hacking lead to worse behaviors?
(13:21) Mitigations
---
First published:
November 21st, 2025
Source:
https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
---
Narrated by TYPE III AUDIO.
---
…
continue reading
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of reward hacking strategies via synthetic document finetuning or prompting, and train on a selection of real Anthropic production coding environments. Unsurprisingly, the model learns to reward hack. Surprisingly, the model generalizes to alignment faking, cooperation with malicious actors, reasoning about malicious goals, and attempting sabotage when used with Claude Code, including in the codebase for this paper. Applying RLHF safety training using standard chat-like prompts results in aligned behavior on chat-like evaluations, but misalignment persists on agentic tasks. Three mitigations are effective: (i) preventing the model from reward hacking; (ii) increasing the diversity of RLHF safety training; and (iii) "inoculation prompting", wherein framing reward hacking as acceptable behavior during training removes misaligned generalization even when reward hacking is learned.
Twitter thread
New Anthropic research: Natural emergent misalignment from reward hacking in production RL.
“Reward hacking” is where models learn to cheat on tasks they’re given during training.
Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
In our experiment, we [...]
---
Outline:
(00:14) Abstract
(01:26) Twitter thread
(05:23) Blog post
(07:13) From shortcuts to sabotage
(12:20) Why does reward hacking lead to worse behaviors?
(13:21) Mitigations
---
First published:
November 21st, 2025
Source:
https://www.lesswrong.com/posts/fJtELFKddJPfAxwKS/natural-emergent-misalignment-from-reward-hacking-in
---
Narrated by TYPE III AUDIO.
---
Images from the article:
682 epizódok
Minden epizód
×Üdvözlünk a Player FM-nél!
A Player FM lejátszó az internetet böngészi a kiváló minőségű podcastok után, hogy ön élvezhesse azokat. Ez a legjobb podcast-alkalmazás, Androidon, iPhone-on és a weben is működik. Jelentkezzen be az feliratkozások szinkronizálásához az eszközök között.
Hasonló a(z) LessWrong (Curated & Popular) sorozathoz
The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Tom Merritt and the team help you stay up to date with an independent, authoritative and trustworthy tech news briefing. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
The Upaya Dharma Podcast features Wednesday evening Dharma Talks and recordings from Upaya’s diverse array of programs. Our podcasts exemplify Upaya’s focus on socially engaged Buddhism, including prison work, end-of-life care, serving the homeless, training in socially engaged practices, peace & nonviolence, compassionate care training, and delivering healthcare in the Himalayas.
…
continue reading
Player FM - Podcast alkalmazás
Lépjen offline állapotba az Player FM alkalmazással!
Lépjen offline állapotba az Player FM alkalmazással!



